Scala Days 2016 is over. I’m sorry I didn’t make it to take notes of all the talks I attended, but some speakers spoke very fluently and my phone is not the best way to write down notes. English doesn’t help as well, and sometimes my understanding of the matter was lagging behind.
So what are my impressions? That’s a good question and I’m not sure about the answer. I think Scala is a very fitting solution for a specific niche. Then as every other programming language can be used for everything (I just heard that Dropbox employs 2.7 million lines of Python code).
The niche I have in mind is made of large, distributed applications, handling zettabytes of streaming data, performing math functions over them. A part of the niche could also be composed by high traffic, highly reliable web services (where service is just a general term and refers to any kind of service, including serving web pages).
In this niche using Scala, with actors and possibly Spark makes a lot of sense.
In other contexts you risk to pay the extra run for something you don’t really need – not every server software needs to scale up, not every process needs to be modeled using events. Although functional paradigm eases writing code that copes with these contexts, you still pay an extra cost.
It is hard to quantify how much. The naïve experiment of having two programmers of comparable proficiency in two different languages working at the same task is very hard to setup.
According to an old research the productivity of a programmer, intended as line per unit of time, is more or less the same regardless of the language. That means, for example, that it is cheaper to write programs in C than in assembly, because C is more expressive and higher level than assembly. I’d like to know if the same holds for Scala, where lines tend to be long concatenation of function applications. For sure this is at a more abstract level, but it requires quite an effort to write, lot of effort to understand and it is close to impossible to debug, at least with today tools.
Well back to my impressions on the state of Scala. Scala is comparatively young and suffers from its youth. There are pitfalls and shortcomings in its design (just as naturally is for every other language) that are starting to be acknowledged by the language owners. The solution they seem to prefer is to rewrite and go for a next incompatible version. This is a dangerous move as Python would teach. Also is somewhat that does not acknowledge the industry. It makes sense for a teaching tool, for a research language, but it impacts badly on industry investments.
In several talks the tenet was that although Scala allows the programmer to chose any of the supported paradigms, only functional programming is the proper way to code. Surprisingly, at least to me, Martin Odersky, the language father, doesn’t agree, when attending a talk, he claimed that multi paradigm was a bless when programming the Scala compiler.
Industry needs pragmatism, but I see it only partially. Enthusiasts may crosses the border to become zealots. And crusades are not something that could bring stability and reciprocal understanding. When I hear about functional programming revolution I am somewhat scared, I prefer evolution, acknowledging the goods of existing stuff and building over them. In revolutions many heads roll, included those of innocent people.
The most widespread background for programmers here was Java. I understand that Java is not the most exciting language. Coming from C++ I find Java quite boring. And, in fact, some, if not many, of the advantages of Scala over Java can be found in C++ as well. Unfortunately C++ falls short of open source industry standard libraries. You won’t find anything in C++ that comes close to what Spark or Akka are for Scala. Also Play – even if it doesn’t encounters a unanimous consensus – is the de facto companion library for web services and web development.
Back to Scala days (again) – it has been a positive experience, some talks needed some preliminary study even if they were marked as beginner (everything pretending to explain implicits). Other talks were quite marketing advertisements in disguise. And some were genuinely fun.
I think I got closer to this language and had great opportunities to change my point of view. My wish is for an ecosystem more attentive to the industry and that values back-compatibility rather than see anything that breaks with the past a way to make easy money by selling technical support.
Implicits inspected and explained
Talk by Tim Soethout. The average age among attendees seem to be higher than other talks, maybe we elders are looking for understanding finally what the hell are implicits (then we would need something similar for monads…). Here we go.
Implicit enables you to use values without explicit reference. Implicit enables the relationship “is viewable as”.
As a parameter the value is taken from the calling context (eg akka sender).
Incomprehensible examples follow.
Implicits are used for DSL, type evidence (whatever this be), reduce verbosity… Other stuff I didn’t make to copy.
Caveats – resolution can be difficult to understand. Automatic conversions. For these reasons better to not overuse.
Implicit parameter just takes the only variable with a matching type as argument.
If two or more variables with a matching types are available an error is reported by the compiler.
Implicit conversion (please avoid them) allows to automatically convert from a type A to a type B every time B is required. This comes handy to convert from and to Java collection types, but it is deprecated. The new approach is to add the asScala method to the Java types.
Implicit view is not understood by yours truly, sorry.
Implicit class. This is used when a class is missing a method. You can write a wrapper to add what you need. If this is declared implicit then when the compiler finds an invocation to the new method the wrapper class is constructed and the method is invoked.
Scoping. Some explanation I didn’t understand. Interactive moment turned quite to an epic failure with most of the attendees having no idea on what was going to happen in the example shown.
Type classes. This concept is used for ad-hoc polymorphism and to extend libraries. A naive approach to serialize to json uses subclasses. All the classes need to inherit from a JsonSerializable and to define the serialization abstract method.
With type class the class to serialize do not need to derive from the same base. A generic trait is defined for the serialization method. By defining implicit variables and assigning them the class which defines the serialization for the specific type then type serializers will be uses when needed.
Other examples just make things worse for me, I though I got it, but now I’m no longer sure (also, now, rereading what I wrote, I’m unsure I understood anything at all).
Wrap up time. I still don’t get this stuff, at least not completely and only slightly more than “danger – do not use”. Type class seems to be really powerful in the sense that they lift Java from its pond to the static polymorphism of C++. But the mechanics that power this specific kind of implicit are still obscure to me. Likely nothing that a good book and some months of hard study couldn’t solve. Just it seems not to be some knowledge you can transfer in a conference.
Transactional event sourcing using slick
Talk by Adam Warski. Event sourcing means that all the changes in the system are captured as a sequence of events.
Reasons for event sourcing: keeping information (not losing info), auditing the information in the system. But it is also useful to recreate the system state.
Hibernate was a technology developed by Adam for Java.
The goal is to have event sourcing with rdbms. There are other approaches (event store, akka persistence, eventuate).
Event is immutable, is the primary source of truth. The payload is an arbitrary json, the name is the case class name. Transaction ID, event ID and user ID.
Events are stored in a dedicated table. A read model is created on the event in the crud. This gives consistency.
DBIOAction[T] gets a description of actions to be done.
User data arrives in the system, within a command (a Scala method). The command uses read to validate the data, if data is valid the command generates a series of actions to perform that updates the model. Event listeners are triggered at this time. Each event listener may trigger further events.
Demo follows for ordering a Tesla model 3.
Summary – no library, just a small adapter. Event listener performs side effects.

The system could have been written with free monads. That would have improved testability. But free monads don’t come for free – you have to pay a price to decode them from the code and figure out what the code is trying to do. As Adam said, maybe it’s just me.
And saying this here while presenting a relational db approach takes really a brave heart.
Connecting reactive applications with fast data using reactive streams.
Talk by Luc Bourlier. As in the previous posts these are my quick notes.
Who doesn’t know what a reactive application is? Responsive, elastic, resilient and message driven – this is what reactive apps are.
Big data means that there are too much data to be handled by traditional means on a single machine.
Fast Data are big data that comes in big volume and you want up to the second information with continuous process.
Spark streaming is the technology by light bend that does the trick.
Spark is an evolution of map reduce model. A driver program (spark context) talks to the cluster manager to get worker nodes to do the job.
Spark can be used on streams by using mini-batching. A mini batch is the work executed on data received in a unit of time.
Spark streaming deals with all kind of failures (hardware, software and network). It also handles recovery for continuous processing and deals with excess of data volume.
A demo is presented with a raspberry pi cluster. (On raspberry pi you don’t need to push the system to the limit, because you are already at the limit).
Demo ran fine, but it broke, that makes me wonder how stable is this technology. The demo model seemed quite simple.
Back pressure is the mechanism implemented by akka streaming to slow the data producer if the consumer is not able to consume data fast enough.
Congestion in spark was handled by static limit on the input rate. In spark 1.5 the limit has been changed into dynamic rate limit. There is a rate limit estimator based on PID that sets the rate limit.
There are some limitations to this method based on the assumptions used in the design – all records require about the same time to process, the process is linear (a 3rd assumption was there, but it got lost my my note taking)
Scala Days – key note
It may not be a great surprise, but the opening key note is held by Martin Odersky. I don’t feel much expectation, more or less everyone expects he’s going to repeat the opening speech of the last Scala conference in New York.
In this post I’ll just summarize the content, my considerations will be in a next one.
Scala days are going to be attended by some 1000 people. Conf app is, of course written in Scala and swift (and it’s open source) courtesy of 47 degrees.
Odersky enters with son et lumier effect, halfway between a disco and an alien abduction… Maybe both.
First he shows a steady growth of the language. Scala jobs get a little over the line. There is no comparison with Java, of course, but there is no drop in popularity.
He will talk about the future, next, mid and distant futures.
What’s next? Scala center, Scala 2.12 , Scala libraries.
Scala center is a vendor neutral initiative supported by several partners that promotes Scala, and undertakes projects that benefit all the Scala community.
Scala 2.12 is the next release of the language, about to be completed. Optimized for Java 8. Shorter code and faster execution.
This release will arrive mid year. Older Java versions will be supported by Scala 2.11 that, in turn, will be supported for quite a while.
Not many new features: 33. Main contributors are from the community.
Martin’s book “Programming in Scala” will be updated to 3rd edition to include release 2.12 of the language.
In the farther future: 2.13 will focus on libraries – Scala collections, simpler, lazy, integrated with Spark. Backward compatible.
Split Scala stdlib into core and platform. Stdlib was much prototypal with the idea that wouldn’t have lasted long.
Scala js, and Scala native.
The dot is the foundation of Scala. a mini language, small enough that programs written in this language can be machine proof. Much of the language can be encoded in this language. 8 years in the working. Language work can be done with much more confidence.

Type soundness, properties of code can be demonstrated (the examples say that an expression of type T produces a value of type T).
Dotty a language close to Scala compiler that produces dot code. Generics are processed with dot. Not ready for industry, but if you want to try something cool…
Faster
Goal: Best language Martin knows how to make.
Dropped: procedure syntax. Rewrite tool that will take care of translating. DelayedInit.
Macros – of was just a long run example. There will be an alternative.
Early initializers – for stuff that needs to be initialized before the base trait.
Existential Types forSome.
General Type Projection T#x.
Added: intersection and union types- types T&U just the common properties of the two types. T|U will have either the properties of T or the properties of U.
Function arity adaptation. Pairs.map ((a,b) =>a+b)
Static method for object.
Non blocking lazy Vals: locking time is much shorter now. Avoiding deadlocks.
@volatile for thread shared lazy vals.
Multiversal equality type safe equality and inequality operators. Named type parameters – partial type parametrization.
Motivations better foundation, safer,…
SBT integration. Repl with syntax highlighting. Intellij. Doc generation. Linker.
Future.
Scala meta – will replace macros and meta programming. Inline and meta. Executed by the compiler.
Implicit function types . used to compose … Just more mess.
Effect checking a->b pure function, a=>b impure. Checked by the compiler.
Nullable types T? =T | Null. Types coming from Java will have a ? Because they have side effect. It is an alternative to monads.
Generic programming.
Guard rails – how to prevent the programmers to misuse or abuse the language. Strategic Scala style: principle of least power. Strategic Scala style.
Libraries that inject bad behavior (eg implicit conversion). Implicit conversions will make a style error if public.
Syntax flexibily. Even Martin regrets the space syntax. Add @infix annotation if the author intends it to be used as infix and give a style error in other cases.
Operators are regretted as well . @infix will have the option to give names to such operators.
Scala center
Notes from “Scala center” by Heather Miller. Scala Center is a non profit organization established at EPFL. It is not lightbend. Same growth chart of yesterday, source are not cited (indeed?). Stack overflow survey reports Scala in the top 5 most loved languages.
The organization will take the burden of evolving and keeping organized libraries and language environment, educating and managing the community rather than the language itself.
Coursera Scala class is very popular (400k) with a high completion rate. There will be 2 new courses on the new coursera platform. Unverified courses are free, verified and certified courses are paid.
Functional programming in Scala – 6 weeks.
Functional program design in Scala – 4 weeks.
Parallel programming – 4 weeks.
Big data analysis in Scala and spark – 3 weeks.
My (somewhat cynic) impression – lot of work and desperate needs for workforce, they are looking to get for free by grooming the community.
EPFL funds for 2 ppl for moocs . donations from the industry and revenues from moocs.
Lightbend? Will continue to maintain the stable Scala.
Package index is not yet available for Scala. Aka people should be able to publish their projects and get them to be used without the need of being a salesperson.
Scala library index. Index.scala-lang.org
It is an indexing engine.
Just wondering – is this a language for the academia or for the industry? Keep changing things and the investments made by the industry will be lost: language is going to change, base libraries are going to change as well… Which warranties do I have that my code will still compile 5 years ahead in the future?
Changing things is good for the academia since it allows to do research and to better teach new concepts. It doesn’t harm the community where workforce is free and there is no lack of people to redo the same things with new tech.
First Sprint
The first sprint is over and it has been though. As expected we are encountering some difficulties. Mainly role keys without enough time to invest in Scrum.
Scrum IMO tends to be well balanced – the team has a lot of power having the last word on what can’t be done, what can be done and how long it will take (well, it’s not really the time, because you estimate effort and derive duration, but basically you can do the inverse function and play the estimation rules to get what you want).
This great power is balanced by another great power – the Product Owner (PO) who defines what has to be done and in what order.
Talking, negotiating and bargaining over the tasks is the way the product progress from stage to stage into its shippable form.
In this scenario it is up to the PO to write User Stories (brief use cases that can be implemented in a sprint) and define their priority. In the first scrum planning meeting, the team estimates one story at time to set the Story Points value.
This is a straightforward process, just draw a Fibonacci Series along a wall and then set a reference duration. We opted for a single person in a week is capable of working for 8 story points. This is just arbitrary. You can set whatever value you consider sound. Having set two-week sprint and being more or less 5 people we estimated an initial velocity somewhere between 80 points per sprint and (having the value) 40 points. The Scrum Master (SM) reads the User Story aloud and the team decides where to put it on the wall. Since the relationship between story points is very evident then it is quite easy and fast to find where to put new stories.
In that meeting, that went well beyond the boxed 2 hours, all the team was there, SM included, but the PO who was ill (the very first day in years). We could have delayed the meeting but the team would have been idling for some days…. not exactly doing nothing, you know there’s always something to refactor, some shiny new technology to try, but for sure we wouldn’t have gone the way our PO would have want us to go.
So we started and in a few moments it became clear that we were too much. Being a project that ranges from firmware to the cloud when talking about a specific story many people were uninterested and became bored and started doing their personal stuff. In the end, we were about three being quite involved in the estimation game.
The lack of the PO in that specific moment was critical – we missed the chance of setting proper priority on tasks since we had to rely on a mail and we can’t ask our questions and get the proper feedback. At the end, we discovered that the topmost prioritaire User Story remained out of the sprint.
The other error we made was to avoid decomposing User Stories into Tasks. This may seem redundant at first, but it is really needed because an User Story may involve different skills and thus different people to be implemented.
The sprint started and we managed to get the daily scrum. This is a short meeting scheduled each day early in the morning where each member of the team says what she/he has done the day before, what is going to do that day and if she/he sees any obstacle in reaching the goal. This meeting is partly a daily assessment and partly an intent statement where, at least ideally, everyone sets the goal for the day. Everyone could assist, but only the team may speak (in fact has to speak).
Daily Scrums were fine, we managed to host one/two programmers that were not co-located most of the time via a skype video call. The SM updated the planned, doing, done walls. The PO attended most of the times.
On the other hand, the team interacted sparingly with the PO during the sprint, but just in part because his presence was often needed elsewhere. Also, I need to say that our PO is usually available via phone call even if he’s not in the office.
This paired with the team underestimating the integration testing and definition of done. Many times user stories were considered done even if not tested with real physical systems, but just with mockups. Deploy process failed silently just before the sprint review leaving many implemented features not demonstrable. Also, our definition of done requires that the PO approve the user story implementation. This wasn’t done for any task before the sprint end, but we relied on the sprint review for getting the approval.
The starting plan included 70 Story Points and we collect nearly another 70 points in new User Stories during the sprint. These new Stories appeared both because we found stuff that could be done together with the current activities or the needed to be done to make sense of the current activities.
Without considering the Definition of Done, we managed to crunch about 70 points that were nearly halved by the application of Definition of Done (in the worst possible moment, i.e. during the Sprint Review).
Thinking about improving the process, probably working from remote is not quite efficient, I noticed that a great deal of communication (mainly via slack, but also via email and Skype) happened the day that those two programmers were off-site.
The sprint end was adjusted to allow for an even split of sprints before delivery, therefore we had something less time than was we planned for.
End/Start sprint meetings (i.e. Sprint Review, Sprint Planning, and Sprint Retrospective), didn’t fit quite well in the schedule, mostly because of PO being too busy in other meetings and activities.
Am I satisfied about the achievements? Quite. I find that at least starting to implement the process exposes the workload and facilitates communication. The team pace is clear for everybody.
Is the company satisfied about the achievements? This is harder to say and should be the PO to say this. I fear that other factors affecting the team speed in implementing the requests of the PO may be considered with the scrum and dumped altogether. Any process poses some overhead and the illusion that a process is not really needed to get the things done is lurking closely.
Today we planned for another sprint, but this is for another post.
Programmer’s Religion Survey
I’m pretty sure that in the common sense programmers are considered rational folks, their minds solidly rooted in facts, comforted by engineering, based on logic, algebra and maths. Brains like knife part truth from lies, dispel doubts and myths.
Well, maybe. What is true is that those who write programs for passion before than for a living, proud themselves to be artists (or at least craftsmen). Artists have inspirations and base their work on inner emotions and use rationality just as a tool when they need it and irrationality as the tool for the other times.
We, programmers, can write code that with is capable to insert a spacecraft in Pluto orbit with astounding precision, while, at the same time we can decide to quit a job if forced to use some tool or process we don’t like.
I tried to be as rational as possible in choosing my tools, programming habits and process, always trying to justify in terms of engineering practice, sometimes changing my gut choice. Recently I confronted with, or, maybe better, have been challenged by colleagues and friends on these matters and long and heated discussions arose.
So I decided to prepare a short poll via surveymokey (even shorter because of the limit for free survey), on the issues that more closely seem to be matter of religion and faith among my friends. Here I’m presenting the result.
As of today I have received 24 poll submission, the poll is still open so feel free to take it, if the exit poll would change significantly in the future I’ll update my analysis. I won’t claim any statistical validity, it is just a poll among friends, likely a very biased set of programmers.
Preferred Text Editor
This is one of the most ancient religion war among programmers, dating well before the advent of PC
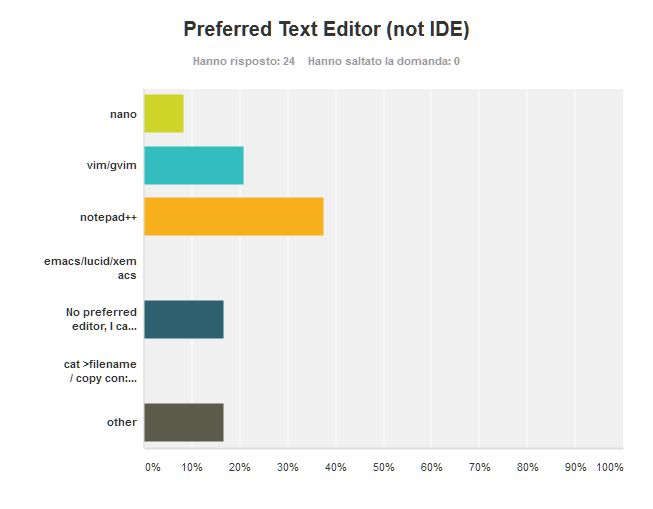
I find interesting that set aside the Windows editor notepad, vim/gvim comes second, winning even over nano which is the other Linux/Unix standard. Emacs seems much dead, which is somewhat surprising when compared to vim. In the other votes I count one and half for Sublime Text, half vote for Atom (which I don’t know), 1/3 vote for notepad++ and two misvotes (I requested no IDE).
My editor of choice is usually vim/gvim, but when I’m on Windows I often and often go for Notepad++. The vim choice was not a straight one because vim is hard to learn. At the beginning, when I used vt100 terminals at the university, I hated it. It appeared like a cumbersome relic from a long gone era. At home I could interactively use CygnusEd on Amiga. But at school we were prevented to use Emacs because the poor HP-UX box we used had just 16M RAM and Emacs made it crash on launch.
Then I came to terms with vi, but I never suggest anyone to learn it, even after I reached a fair proficiency. There are two main reasons that make vim my preferred editor. First it is available on every Unix machine. Maybe you find nano or pico or even emacs or none of them, it depends on the distribution, on the system. But vi, if not vim, is there for sure. Also consider that now linux is used also on embedded systems that are still resource constrained so chances are that you can’t install the editor you want. The second reason is that when you have a slow/intermittent (or blind) connection nothing beats vi. You count how many columns you want advance, how many characters you want to delete, where to insert and with a single command you instruct the editor to do what you want. Try to move the cursor 10 columns forward on an intermittent connection using a conventional editor by pressing repeatedly the right arrow key. Are you sure you pressed it ten times? And that the editor on the other side of the Moon received 10 keypresses? How confident you are? Well with vim you are sure of what you have done. On the other hand if you happen to have the wrong keyboard layout…
Indent Technique
Indentation is a need for readability in many programming language, in some it is even needed for proper compilation. There are two basic techniques whose origin is lost in the dawn of electrical typewriters – spaces and tabs.
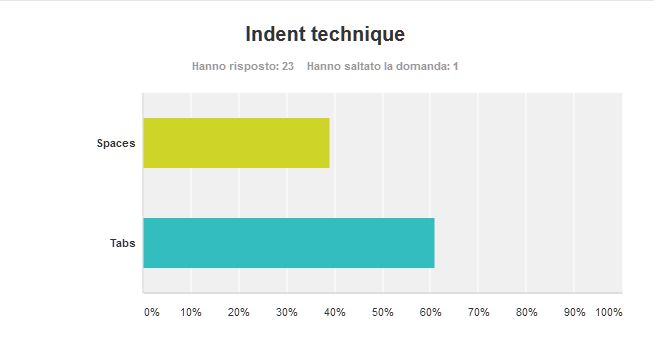
The advantage of tabs is that you can use editor/IDE preferences to set the preferred width, so the indent could always please your taste. But tabs mixes badly with spaces, so a file that mixes both spaces and tabs may become messy if it is viewed with a tab size different from the one used to write the file. Also sometimes you need an indent level not aligned with standard indentation levels (e.g. when you need to split a long line). In this case you are force to use the spaces, causing the file to mess up again if viewed with a different tab size.
Spaces may be a bit more dull, but they are reliable – always you see what you have, the file appears always the same regardless of user preferences. That’s why I found the result of this poll interesting.
As properly pointed out by a friend of mine – you should use tabs for indentation and spaces for alignment. That makes a lot of sense, but it is pretty hard to enforce without entering quite heavily in the syntax of the language being edited.
Indent Column
Still about indent, this question asked the preferred indent size. Keeping a wide indent size hints the programmer at avoiding too nested code, since quickly the code goes out of the right margin. That’s why I prefer a quite wide indent at 4 columns. I found so may colleagues and friends agree with me:
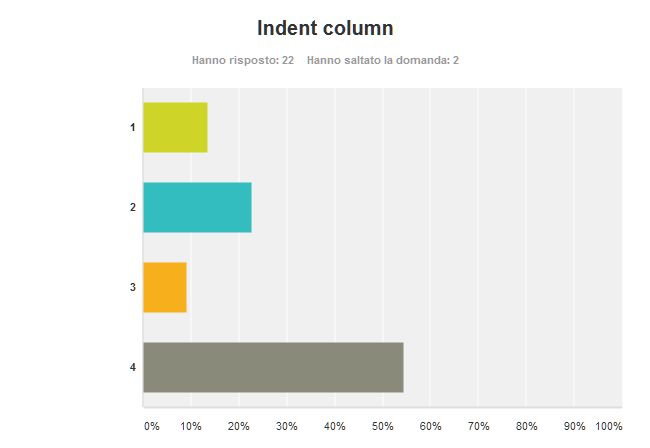
Interestingly enough – the sum of all the votes for indentation lesser than 4 is not greater than the votes for indentation 4. Surprisingly there two people love single column indent! That option was more of a joke than an option I would take seriously.
Opening Brace Position (Brace=open block symbol)
Braces are used to define blocks of instruction in many languages whose ancestry can be tracked, more or less easily, back to BCPL (even if I would have some difficulties to see such lineage in Scala). In this sense there are several styles about the placement of the opening brace. The C Language by Kernigham & Ritchie used the open brace at the end of the statement that defines what kind of block is. Allman style, used initially to write most of the BSD utilities, uses braces in the same way Pascal-like languages use begin/end, i.e. on a line alone aligned with the statement. GNU is a third popular indent style and requires the opening (and closing) brace to be on a line alone, half indented between the statement and the inner block code.
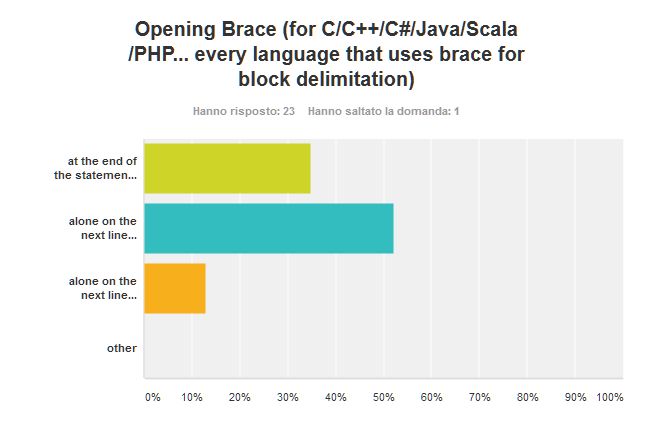
Once again my preferred style won. I like the symmetry of the matching parenthesis the helps in reading the code and hints the programmer to keep the code short because some lines have to accommodate braces. The denser the code the harder to read.
Also I think that is interesting that I changed my style – I started with K&R style (pretty obvious since I started coding C before the ANSI standard was out). Then, when switching to C++ back in the early ninenties, I read the Ellemtel Rules and Recommendation. Those rules made a lot of sense and provided rationale for every rule. So that I was convinced to switch brace style. Lesson learned, if it makes sense, you can change your habit (or religion).
The GNU style scored quite low, maybe that half indentation is not that appealing.
Language of Choice
At the beginning it was just machine code, no one could disagree. Then it came Fortran, Lisp and Cobol (but the real story is a bit more complex) and suddenly there were four religions (not three, because there were those claiming that machine code was still the best). For my poll, I picked 5 popular languages and Antani an esoteric language. (this is a mistake – the right name is Monicelli instead of Antani, sorry).

Once more surprisingly the preferred language is C++, which matches my preferences (I swear I didn’t rig the poll). With a C# second, on which I agree and third C. I am afraid that the poll group was very biased in this respect, especially when compared with official indexes such as TIOBE.
Thanks god no one chose Antani, but no one had a different preference other than the ones listed. Given the zillions of programming languages I had expected at least one vote in other.
Scripting Language of Choice
Scripting languages are the glue of the software, they allow with a moderate effort to combine components are tools to provide advanced and sometimes surprising results. The difference between a general purpose language and a scripting one may be thin in some cases and I think there is no clear answer. Python, Visual Basic, Ruby and Lua may have roots in scripting, but they aim to or are used as languages to create general purpose software.
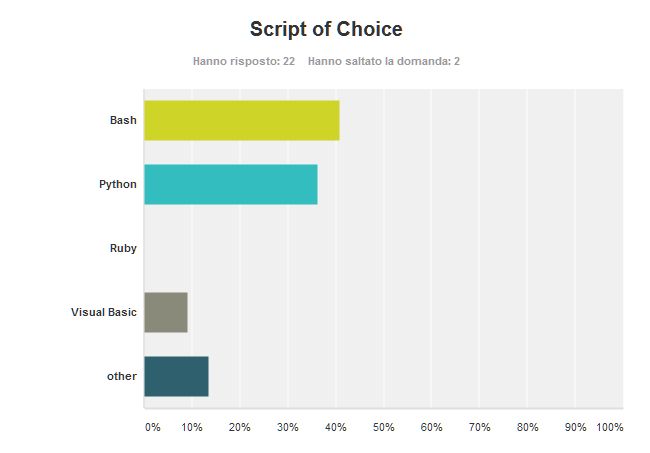
Bash is my preferred scripting language. The latest version has a number of features that allows complex programs to be written. In its evolution lost a bit of cryptic aspects letting the programmer use more sensible constructs, but it is still a language with some obscure constructs. Hardly you can beat bash in the Unix/Linux environment when you have to automate the command line. Since in Unix/Linux you can do everything from the command line, bash allows you to automate the entire system.
The shortcomings of bash, notably a survival level of math handling, the lack of user defined structured types and no native support for binary files, do not prevent the guru programmer to use bash for everything. A more convenient way is to use Python that is based on a more modern design and can rely on many and disparate libraries.
So I expected Python to collect more votes than bash (even if bash is my preferred one).
other collected 1 vote for JavaScript (which indeed is a scripting language), 1 vote for Lua (another pretty scripting language very simple although flexible) and 1 vote for Perl (another Unix/Linux favorite).
Ruby got no sympathy, although at least one noteworthy web application is written in this language.
Web Server Language
Many (most of?) applications are written today as web applications. Languages used to code these programs are to be chosen carefully, long are gone the times when a CGI interface and some shell scripts could do the trick of making web pages dynamic.
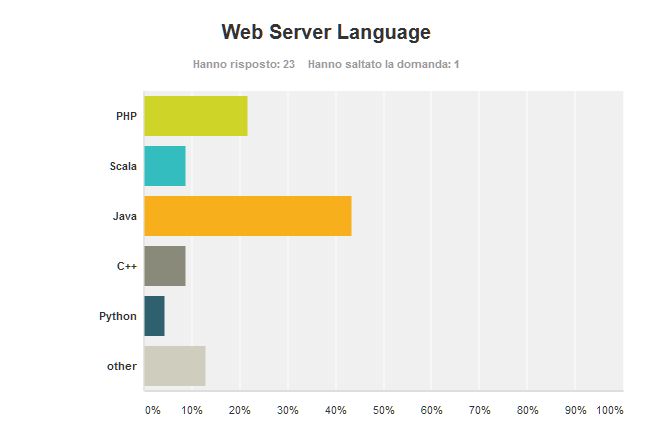
If traditional applications are to be developed in C++ according to the majority of my friends, not so for web applications. Here Java is king getting twice the votes of the runner up – PHP. PHP being specifically developed for this task is a natural second. Surprising Scala and C++ are considered at the same level for this application.
In the other section I got one vote for NodeJS, one vote for C# and one vote for no preference (so my fried who voted for no preference, next time you can program a web application in Monicelli… :-D).
IDE
The IDE is a relatively recent concept in programming, I would date it around early eighties, at least in its modern form. Before you had several different and sparse tools to do your programmer job – an editor, then a compiler, a linker and possibly a debugger (interestingly enough on home computers you had just one environment which could be considered a rudimentary form of IDE). IDE started to appear in systems with no multiprocessing capabilities such as CP/M and MS-DOS. The first I’ve seen and used, which incidentally was also the first IDE, was Turbo Pascal on the CP/M operating system.
Nowadays complex projects are preferably managed by IDE even when they come with a build system recipe (be it make, ant, maven or sbt).
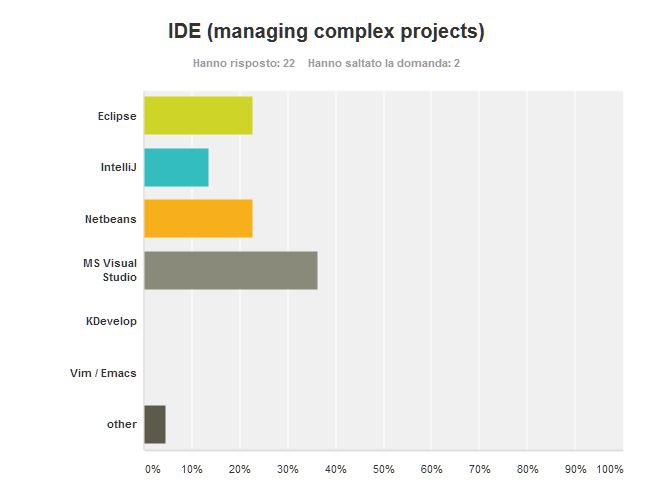
Microsoft Visual Studio is the oldest among the choice and the one who got most votes. I fully agree, Visual Studio is a powerful and comprehensive solution that long has long the lock-in-Microsoft nature it had at the beginning. When I can’t used Windows, my preferred IDE is Netbeans. On the other hand I can’t stand Eclipse. It is a bloated application with no rational design in its interface. Eclipse subsystems seem to be attached as a second thought and they don’t share the same way of using variables, or doing things. Too bad that Eclipse is the chosen platform by many vendors to implement their specific development environments. Consider NXP (former Freescale) that provides KDS to develop for their Kinetis processors. You could setup a different IDE, but you would have serious trouble in finding configuration parameters especially for the debugger.
IntelliJ is a fair alternative to Netbeans, I’ve used it for a while with Scala and I think the shortcomings of the IDE are more in attempting to understand a cumbersome language than in the IDE itself.
When writing the poll I forgot about Xcode the Apple proprietary IDE. Apple doesn’t trigger my enthusiasm, I never used XCode, but I heard it is jolly good. Though it is the only IDE in the list that works only on a proprietary hardware.
I expected some sympathy for KDevelop and Emacs (if not vim), but they got any.
Build Systems
What use is a build system today when we have such powerful IDEs? Well, first you may want to build the application in batch mode (though some IDEs support batch mode) or you don’t want to force a specific IDE on the users of your code or your IDE saves the project in a location dependent fashion (Eclipse?).
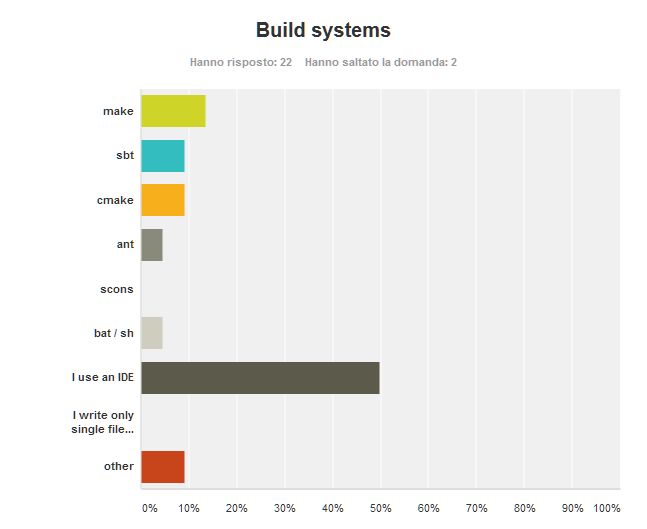
Unsurprisingly more than half of my esteemed friends and colleagues noted that using their preferred IDE they don’t need any stinking build tool. So true, but I still prefer to have something simpler if a full IDE is not needed.
Make is both the first build tool and my preferred option. Before make programs where build using shell scripts (an option that has still a supporter according to my poll). I had a look at ant when it appeared to manage the build of Java application. My impression was that ant was just a different way to write makefiles, so there was no gain in learning a different system. Cmake is somewhat similar.
Sbt is the tool for building (and managing I would say) Scala projects. It is an over-weighted tool that starts to download internet on your pc the first time you launch it. Then it relies on a repository to store and retrieve different versions of the libraries and eventually manages to build Scala applications hiding the warning messages coming from the underlying tools. As you may have guessed, I can’t stand it.
Others make me notice that I left out maven and gradle (one vote each).
Version Control System
Tenth and last question, what is your preferred version control system? A version control system is a system that takes care of the history of your source code, so it is quite an important part of the development.
In the workplace we had quite a flaming discussion over which is the version control system to use, split in half (me on one side, my colleagues on the other) we were among subversion and git supporters.
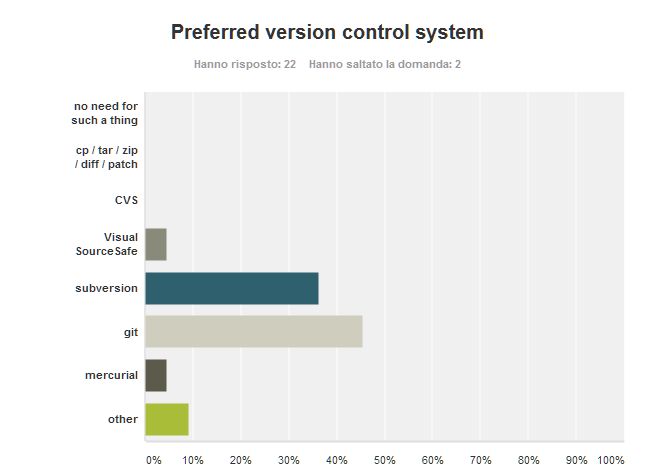
Thankfully no one in her/his right mind thinks that there is no need for such a thing as well as that this management can be done without specialized tools (i.e. using basic tools like tar, zip and the likes).
Also CVS is gone the way of the Dodo, as it should, but without taking with itself Visual SourceSafe, as it ought. Visual SourceSafe is the Microsoft attempt a VCS and the version I used was quite crappy.
Subversion and Git make most of the votes and are quite close each other with, to my grief, git leading.
I find the subversion promotes a better cooperation in the team and avoids the need for a Software Configuration Manager. You have a single central authoritative repository, with a story fixed (as fixed can be data). The team must proceed by small commits and frequent updates. If care is taken not to commit code that breaks the build, then this is a very convenient way to proceed.
Git has been written from a very different need – suppose you are a maintainer of a project. Of course you want to have control of what the contributors to the project are contributing. Maybe you want to bugs to be fixed, but not some new features, or you want to be very careful about the code written by a specific programmer. You need an easy way to add and remove single commits, merge and go back if anything is wrong.
But when you apply git to a development team you run the very high risk to have every developer with a different version of the codebase, with a central codebase out of date or not consistent because there is no such thing as a maintainer.
Nonetheless my team promised me a tenfold increase in productivity if we replace subversion with git, so I opted for the wrong tool. We are about to switch, and this could be some stuff for another post.
Anyway there are some other VCS – beside mercurial, also perforce got a single vote. I got a vote also for none at the moment.
I hope you enjoyed taking the poll and reading my comments at least as much as I enjoyed writing the poll and reading your answer. Your comments are welcome, after all this is about religions, I would be disappointed if no flaming comment would appear :-).
Unboxing SALEAE
In his autobiography – I Am Spock – famous actor Leonard Nimoy wrote that when he started shooting Star Trek he was given a pair of lousy pointy ears props from the production. He found no way to make them look real, nor to stand still on the top of his ears. So he decided to shell out his own money and get some real props.It is always difficult, when you are passionate about your work, to draw a line to constrain your involvement. In the same way I don’t like the precision scale approach – i.e. stopping exactly at my duty edge.
So I decided to overcome some internal bureaucracy problems of my employer and buy a logic state analyzer to do my job. Waiting official channels would have taken a time not compatible with project deadlines.
I opted for a Saleae (the cheapest one – I don’t need anything more… and, well, that’s still quite some money) and placed an on-line order on Batter Fly. No shipping fees, I got the package in two days… great service (just beware – they show prices on the site without the VAT, surprise is saved for checkout time).
 |
Here is the box, very light… Suspiciously light, hadn’t they bothered to put at least a brick inside? |
 |
No brick, apparently nothing. But my cat Trilli looks very interested in the chips |
 |
Here it is. |
 |
The logic state analyzer is very small. From the picture I’ve seen I thought it was at least twice the size it actually is |
 |
In the bag, aside from the logic analyzer itself, there are – connection wires, probes, USB cable and a thank you postcard that doubles as a quick guide. |
Demotivational Poster
Yesterday my old friend Jimmy Playfield found a motivational poster on the wall beside his desk. Usually it is quite hard to find a motivational poster that is not lame or, worse, demotivational. And the motto on the wall was quite belonging to the latter. An ancient Chinese proverb quoted: “The person who says that it cannot be done should not interrupt the person doing it”. The intent, possibly, was to celebrate those who, despite of the adverse situation and the common sense, heroically work against all odds to achieve what is normally considered impossible.
Unfortunately reality is quite different. As that famous singer optimistically sang – One among thousand makes it. That sounds like a more accurate estimation for those trying to attain the impossible. And likely, I would add, that one is the person who benefits from advice and help from friends and co-workers.
Human kind didn’t reach the moon just because someone was kept away from those who said it wasn’t possible. To achieve the impossible you need a great team fully informed on why and how your goal is considered impossible. Usually great management and plenty of resource is helpful, too.
Just reminding a lesson at the University. The teacher, made this example: “Microsoft, in the search for new features to add to their compilers line may find that adding non termination detection would be great. Imagine, you write the code and the compiler tells you that no way, under these condition, your code will hang forever in some hidden loop. Wouldn’t it be really helpful? But this is not possible and it has been proved by Turing”. But… According to the motivational post, no one would be expected to tell the marketing and the poor programmer that volunteered for implementing the feature, that no matter how hard he tries, that feature is simply not possible (at least on Turing machine equivalents).
So that motivational sentence is basically against team work, informed decisions, information sharing, risk management.
A witty saying doesn’t prove anything [Voltaire], but sometimes it is just detrimental.
Well, I was about to close here, but I just read another quote by Voltaire: “Anything too stupid to be said is sung.” Well… that makes a good confrontation between Morandi and Voltaire.