“I’m going to attend this conference, is anyone else coming?” texted my friend Sandro in our group chat.
“What’s it called?” I replied.
“Software You Can Love.”
“Sold! How could I miss it?”

“I’m going to attend this conference, is anyone else coming?” texted my friend Sandro in our group chat.
“What’s it called?” I replied.
“Software You Can Love.”
“Sold! How could I miss it?”

If you have kept up to date with the latest developments of C++, for sure you have noticed how convoluted and byzantine constructs and semantics have become.
The original idea of a C with Classes at the root of language is long lost and the fabled smaller and cleaner language hidden inside C++ is ever more difficult to spot and use.
The combo – backward-compatibility latch and committee-driven approval/refusal of proposals, make the language evolution spin around. Missing or late additions to the language are sitting ducks, and the lack of networking in the standard library, for a language that is 40, is enough to tell how poorly the evolution of the language is handled.
Continue reading “Nothing lasts forever, but Cobol, Fortran, and C++”Recently I listened to a “Happy Path Programming” podcast episode about Smart Types. And that inspired me for this double post. The first part (this one) is about what a smart type is and why you should employ smart types in your code. The second part (yet to come, hopefully soon) is about the troublesome way I implemented an arithmetic smart type template in C++.
Continue reading “As Smart as a Smart Type – Theory”Recently I had the questionable pleasure of watching “Cosmic Sin” courtesy of Netflix. The movie is a sci-fi show starring Bruce Willis. I was lured into wasting my time on it, by the trailer promising a space-operish feat and I took the presence of such a star playing in the movie for a warranty on quality. I couldn’t be farther from the truth.
The movie plays out confusingly, lacking a coherent script and motivated actors, pushing the watcher into an undefined state (not UB luckily). The helpless watcher, astonished by how bad a film could be, hopes until the very last for something interesting and entertaining to happen until the mixed relief-disbelief emotion of closing titles puts an end to the suffering.
When thinking about C++ and functional programming I have some of the feelings I had watching the movie. Before being persecuted by my friends from the C++ community I have to make clear that C++ is not that bad, although there are some similarities.
Continue reading “Is C++ Ready for Functional Programming? – Wrap Up”
Featured image vector created by brgfx – www.freepik.com
Although functional programming can be done in a dynamically typed language (Lisp, the functional programming language forerunner, had no types), strong static type adds a very natural complement to functional programming.
From a mathematical point of view, a function sets a relationship between the set defined by the function argument (domain in math speaking) and the corresponding results (co-domain). Algebra studies exactly these relationships and may help the programmer in proving certain properties of the functions composing the programs.
Algebraic Data Types (ADT) are aggregated types in the algebra context. Two ADTs are of particular interest – sum types and product types. With sum and product referring to the resulting number of possible values (i.e. cardinality of sets).
Continue reading “Is C++ Ready for Functional Programming? – Types”
Well, I’m running out of anti-patterns and oddly looking code from the legacy of my job-ancestors. I thinks that there are a few that are worth mentioning but don’t build up to a stand-alone post, and then its space for questions and discussions and whether exists or not a way out.
Continue reading “Our Father’s Faults – Wrapping it up”
When I started this job and faced the joyful world of Scala and Akka I remember I was told that thanks to the Actor model you don’t have to worry about concurrency, since every issue was handled by the acting magic.
Some months later we discovered, to our dismay that this wasn’t true. Or better, it was true most of the time if you behave properly, but there are notable exceptions.
Continue reading “Out Fathers’ Faults – Actors and Concurrency”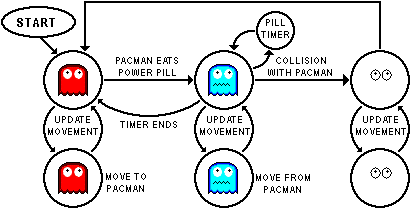
This post is not really specific to Scala/Akka, since I’ve seen Finite-State Machine (AKA FSM – not this FSM) abuse in every code base regardless of the language. I’ll try to stick with the specificities of my code base, but considerations and thoughts are quite general.
FSM is an elegant and concise formal construct that helps in designing and encoding and understanding simple computational agents.
Continue reading “Our Fathers’ Faults – Actors – Explicit State”
This is the second part of the post on why Actors and OOP are really a bad match. In the last post we have seen how adding types and methods to actors could turn into a bad idea, now we look at another aspect of OOP – actors and inheritance.
Once you have wrapped an actor inside an object as our fathers did, you can hardly resist the temptation of composing by inheritance. On paper this is also a good idea, think for example to some sort of service that has some housekeeping to do (registering/unregistering clients, notify clients), what’s wrong in having a base class Service from which LedService can be inherited?

This was intended to be a single comprehensive post about what’s wrong in mixing the Actor model with OOP. After a while I was writing this I discovered that there is a lot of stuff to be told, so I split the post in two. This is the first and talks about why you would like to add typing to Actors and then why you would like to get back. The next one (that I would likely publish in 2020) is about why you would like to add inheritance among actors and why guess what… you would refrain to do it. Let’s start.
Once that the concept of Actor as implemented by the Akka framework is clear, we can proceed to the first issue in mixing Actors and OOP, that is brilliantly depicted by the sentence “No good deed goes unpunished”.
Continue reading “Our Fathers’ Faults – Mixing Actors and OOP 1, Actors with methods”