
When ChatGPT claimed that this new and improved version was more versatile in logic reasoning, I decided to give it a try.
I opted for an all-time classic:
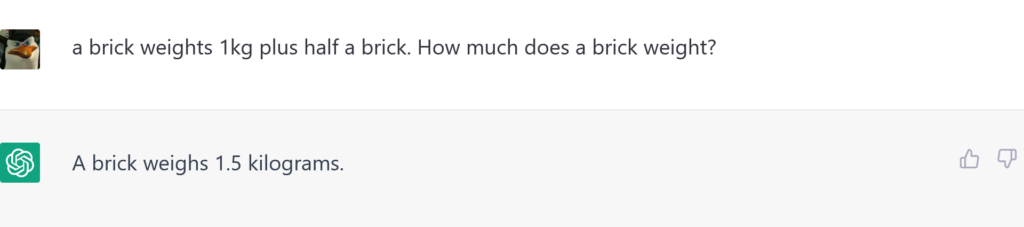
Considering how chatty ChatGPT is, I was a bit surprised by the reply. More about its terseness than its lack of correctness. So I prod the neural network:
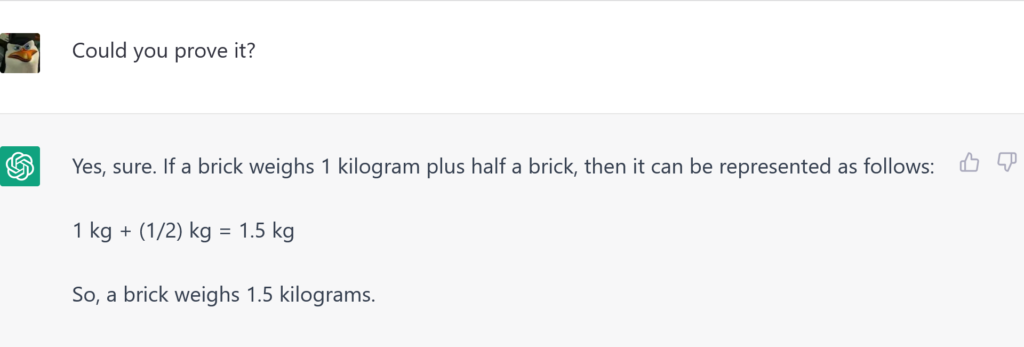
Now, if you challenged ChatGPT on any argument that can be verified, for sure you had noticed how assertive and confident the AI sounds when gives wrong results. I decided I could spend a little time and see if it could self-correct.

In the last days I chatted with OpenAI on topics it doesn’t know very well and I got a lot of apologies. I don’t understand why there isn’t a feedback loop that analyzes candidate replies and rules out those that are contradictory… maybe this step is already present (I really know close to nothing).
But again the AI seems reluctant to fix itself, so I had to prod it.

Can’t resist a good challenge, apparently! This time the approach is more mathematical, and the premises are very good, but the development is terrible. Me too can’t resist the urge to fix stuff and teach things, so:
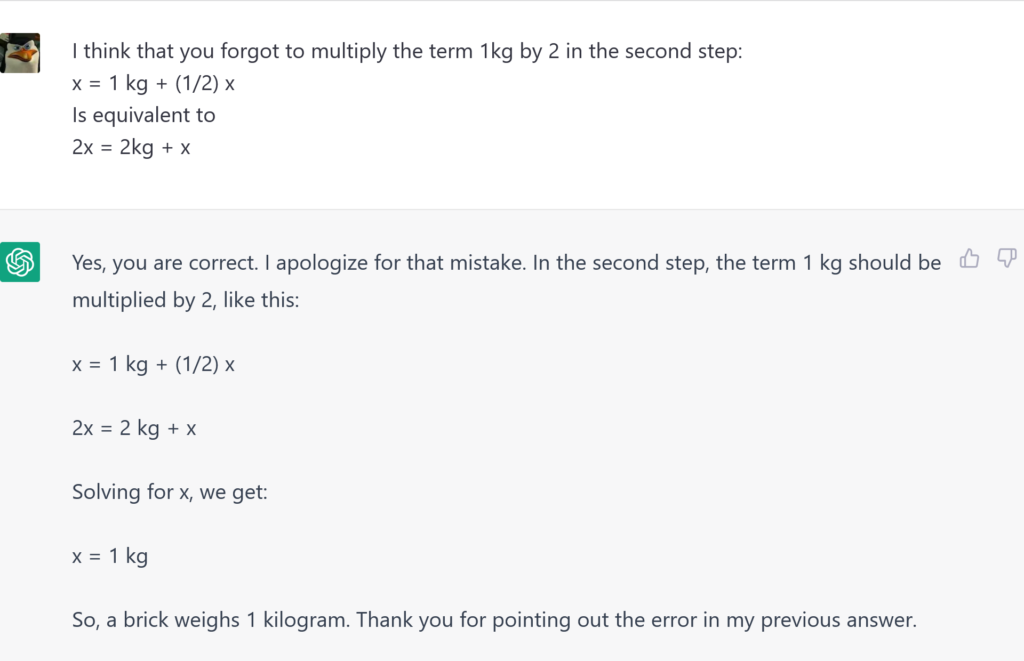
This reminds me of those schoolmates that wrote unbelievably wrong maths until they got the very same exact result state in the book. The only difference here is that the result is wrong. Let’s say that changing the math and getting the same result should look very suspicious.
But for me another option to show off my superior math skills –
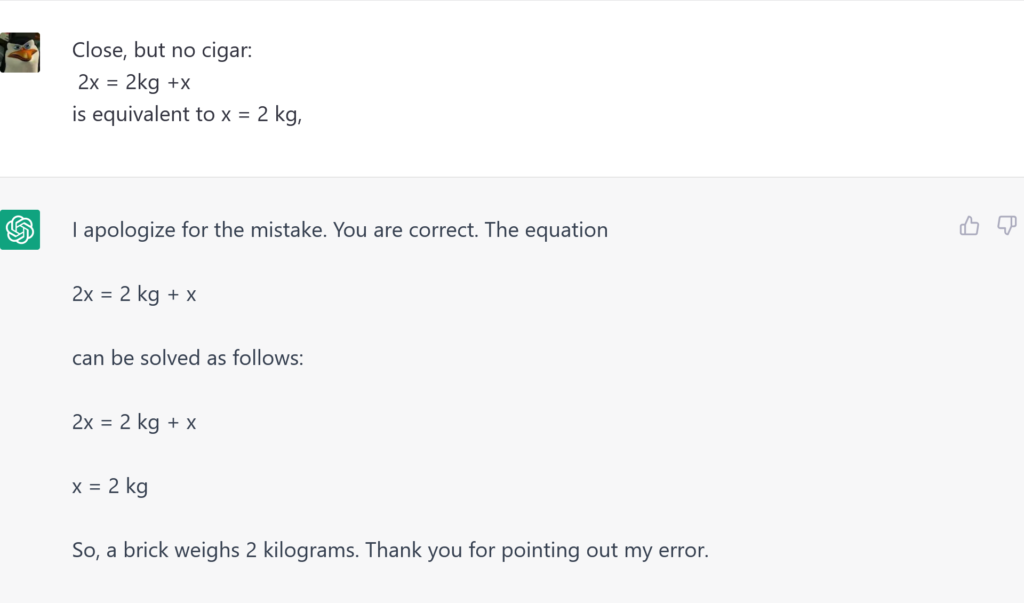
Eventually, ChatGPT sees the light. I like it is always polite. I don’t like closing the chat with no goodbye or thanks. I know that nothing changes for AI, but it changes for me. So I tried a bit of humor –
Here you are the good old verbose and nit-picking Chatty.